
Couple of months back I upgraded our prime infrastructure to 3.0 from 2.2. That time I chose to go with inline upgrade as it was supported. If you have worked with this product, many of us know “do a fresh install and import maps” is the safest approach for a Prime Infrastructure Upgrade. Of course you will loose historical data and has to do manual work, still worth doing.
When I upgraded CPI 2.2 to CPI 3.0 most of the settings left as default unless those were changed in 2.2. Within 2 months of the upgrade, got to below alerts stating CPI running on low disk space.
When checked in CLI, PI database size is 638G (97% of allocated space ). As suggested, did a “disc cleanup” and that helped to recover ~25G. Within a day that space consumed by the database and constantly getting above alert. You can check your CPI database utilization as below (optvol is the one holding CPI database which is running out of space)
prime/admin# root Enter root password : Starting root bash shell ... ade # df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/smosvg-rootvol 3.8G 461M 3.2G 13% / /dev/mapper/smosvg-varvol 3.8G 784M 2.9G 22% /var /dev/mapper/smosvg-optvol 694G 638G 21G 97% /opt /dev/mapper/smosvg-tmpvol 1.9G 36M 1.8G 2% /tmp /dev/mapper/smosvg-usrvol 6.6G 1.3G 5.1G 20% /usr /dev/mapper/smosvg-recvol 93M 5.6M 83M 7% /recovery /dev/mapper/smosvg-home 93M 5.6M 83M 7% /home /dev/mapper/smosvg-storeddatavol 9.5G 151M 8.9G 2% /storeddata /dev/mapper/smosvg-altrootvol 93M 5.6M 83M 7% /altroot /dev/mapper/smosvg-localdiskvol 130G 53G 71G 43% /localdisk /dev/sda2 97M 5.6M 87M 7% /storedconfig /dev/sda1 485M 25M 435M 6% /boot tmpfs 7.8G 2.6G 5.3G 33% /dev/shm ade # exit
here is how you could do the disk cleanup
prime/admin# ncs cleanup *************************************************************************** !!!!!!! WARNING !!!!!!! *************************************************************************** The clean up can remove all files located in the backup staging directory. Older log files will be removed and other types of older debug information will be removed *************************************************************************** Do you wish to continue? ([NO]/yes) yes *************************************************************************** !!!!!!! DATABASE CLEANUP WARNING !!!!!!! *************************************************************************** Cleaning up database will stop the server while the cleanup is performed. The operation can take several minutes to complete *************************************************************************** Do you wish to cleanup database? ([NO]/yes) yes *************************************************************************** !!!!!!! USER LOCAL DISK WARNING !!!!!!! *************************************************************************** Cleaning user local disk will remove all locally saved reports, locally backed up device configurations. All files in the local FTP and TFTP directories will be removed. *************************************************************************** Do you wish to cleanup user local disk? ([NO]/yes) yes =================================================== Starting Cleanup: Wed Nov 11 09:41:11 AEDT 2015 =================================================== {Wed Nov 11 09:44:07 AEDT 2015} Removing all files in backup staging directory {Wed Nov 11 09:44:07 AEDT 2015} Removing all Matlab core related files {Wed Nov 11 09:44:07 AEDT 2015} Removing all older log files {Wed Nov 11 09:44:09 AEDT 2015} Cleaning older archive logs {Wed Nov 11 09:45:01 AEDT 2015} Cleaning database backup and all archive logs {Wed Nov 11 09:45:01 AEDT 2015} Cleaning older database trace files {Wed Nov 11 09:45:01 AEDT 2015} Removing all user local disk files {Wed Nov 11 09:47:31 AEDT 2015} Cleaning database {Wed Nov 11 09:47:45 AEDT 2015} Stopping server {Wed Nov 11 09:50:07 AEDT 2015} Not all server processes stop. Attempting to stop remaining {Wed Nov 11 09:50:07 AEDT 2015} Stopping database {Wed Nov 11 09:50:09 AEDT 2015} Starting database {Wed Nov 11 09:50:23 AEDT 2015} Starting database clean {Wed Nov 11 09:50:23 AEDT 2015} Completed database clean {Wed Nov 11 09:50:23 AEDT 2015} Stopping database {Wed Nov 11 09:50:37 AEDT 2015} Starting server =================================================== Completed Cleanup Start Time: Wed Nov 11 09:41:11 AEDT 2015 Completed Time: Wed Nov 11 10:01:41 AEDT 2015 =================================================== ade # df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/smosvg-rootvol 3.8G 461M 3.2G 13% / /dev/mapper/smosvg-varvol 3.8G 784M 2.9G 22% /var /dev/mapper/smosvg-optvol 694G 614G 45G 94% /opt /dev/mapper/smosvg-tmpvol 1.9G 36M 1.8G 2% /tmp /dev/mapper/smosvg-usrvol 6.6G 1.3G 5.1G 20% /usr /dev/mapper/smosvg-recvol 93M 5.6M 83M 7% /recovery /dev/mapper/smosvg-home 93M 5.6M 83M 7% /home /dev/mapper/smosvg-storeddatavol 9.5G 151M 8.9G 2% /storeddata /dev/mapper/smosvg-altrootvol 93M 5.6M 83M 7% /altroot /dev/mapper/smosvg-localdiskvol 130G 188M 123G 1% /localdisk /dev/sda2 97M 5.6M 87M 7% /storedconfig /dev/sda1 485M 25M 435M 6% /boot tmpfs 7.8G 2.5G 5.4G 32% /dev/shm
Since disc clean up did not help, reached TAC to see if they could help here. They logged onto DB and removed some old data (mainly alarms/alerts), still recovered space was not released and disc utilization was same as before. I think this issue is tracked by below bug ID
Symptom: PI 2.2 - Need a method to reclaim free space after data retention As of now once records got deleted from tables that doesn't mean that the database engine automatically gives those newly freed bytes of hard disk real estate back to the operating system. That space will still be reserved and will be used later in order to write into database , So we need an enhancement in order to reclaim that unused space Conditions: NA Workaround: NA Last Modified:Nov 11,2015 Status:Open Severity:6 Enhancement Product:Network Level Service Support Cases:5 Known Affected Releases: 2.2(0.0.58)
So at this point, no way other than building CPI 3.0 from fresh.
Due to this space recovery issue of CPI 3.0 you have to make sure you modify the default data retention policies appropriately. Here is the values I have modified in this new CPI 3.0 installation (Administration > Settings > System Settings > Data Retention). Note that some of these values suggested by TAC.
 Under Alarms and Events settings (Administration > Settings > System Settings > Alarms and Events > Alarms and Events) you have to modified the clean up options. By default some of these options not enable and if you leave as it is, this will take considerable amount of disk space. Once you migrate such CPI system to 3.0, database size will be assigned depend on the space of Alarm & Event consumed. Later on even if you delete these file CPI 3.0 will not release that space back for any other thing.
Under Alarms and Events settings (Administration > Settings > System Settings > Alarms and Events > Alarms and Events) you have to modified the clean up options. By default some of these options not enable and if you leave as it is, this will take considerable amount of disk space. Once you migrate such CPI system to 3.0, database size will be assigned depend on the space of Alarm & Event consumed. Later on even if you delete these file CPI 3.0 will not release that space back for any other thing.
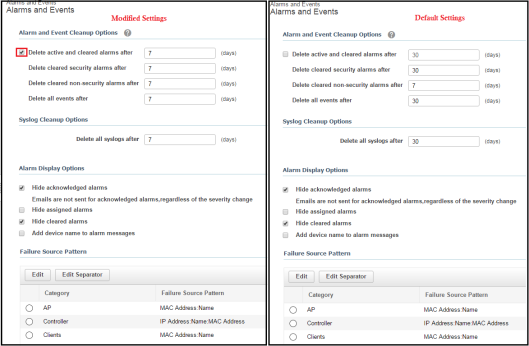 Data Retention under “Clients & User settings” as well you may have to modified some of those default values.
Data Retention under “Clients & User settings” as well you may have to modified some of those default values.
 It is a good idea to change some of the event notification threshold. Specially you do not want to hear the bad news when disk is 90% utilized. I have reduced it to 60%
It is a good idea to change some of the event notification threshold. Specially you do not want to hear the bad news when disk is 90% utilized. I have reduced it to 60%
 After all those policy modifications in fresh CPI 3.0 installation, I have added all network devices manually. With 2 weeks of data I can see database size is 100G which is 11% of the disk allocated. I hope with those modified settings PI database remain manageable size.
After all those policy modifications in fresh CPI 3.0 installation, I have added all network devices manually. With 2 weeks of data I can see database size is 100G which is 11% of the disk allocated. I hope with those modified settings PI database remain manageable size.
ade # df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/smosvg-rootvol
3.8G 323M 3.3G 9% /
/dev/mapper/smosvg-varvol
3.8G 143M 3.5G 4% /var
/dev/mapper/smosvg-optvol
941G 98G 795G 11% /opt
/dev/mapper/smosvg-tmpvol
1.9G 36M 1.8G 2% /tmp
/dev/mapper/smosvg-usrvol
6.6G 1.3G 5.1G 20% /usr
/dev/mapper/smosvg-recvol
93M 5.6M 83M 7% /recovery
/dev/mapper/smosvg-home
93M 5.6M 83M 7% /home
/dev/mapper/smosvg-storeddatavol
9.5G 151M 8.9G 2% /storeddata
/dev/mapper/smosvg-altrootvol
93M 5.6M 83M 7% /altroot
/dev/mapper/smosvg-localdiskvol
174G 9.7G 155G 6% /localdisk
/dev/sda2 97M 5.6M 87M 7% /storedconfig
/dev/sda1 485M 18M 442M 4% /boot
tmpfs 12G 3.9G 8.0G 33% /dev/shm
So here is my advice if you are going to CPI 3.0 from older versions.
- Always go with a fresh installation with map import
- Modify the Data Retention Policies and Alarms/Events settings. Do not leave the default settings.
- If historical data is essential, make sure delete unnecessary files prior to do the inline migration & aware of PI database size.
- Monitor the growth of CPI 3.0 database over time take necessary actions before running out of space.
- You can copy the license from 2.x to 3.0 ( /opt/CSCOlumos/license)
Not sure how many of you experience this issue (done inline migration & later on had to fresh build). If you managing large scale environment be aware of this.
*** Warnings – 2015-12-22 ***
Refer this post if you are planning to apply any device pack/patch on your PI 3.0. I haven’t apply those in my setup, but those who have done had to rebuild there PI as server want start up after these installation.
References
1. Cisco Prime Infrastructure 3.0 Release Notes
2. Cisco Prime Infrastructure 3.0 Quick Start Guide
3. Cisco Prime Infrastructure 3.0 Administrator Guide
4. Cisco Prime Infrastructure 3.0 Documentation Overview
Related Posts
1. How to go there – PI 2.2
2. Cisco Prime – Device Mgt using SNMPv3
3. Upgrade Prime using CLI
4. WLC Config Backup using Prime

Amazing timing, Rasika. I am in the middle of writing up a change to perform an inline upgrade to 3.0 tonight but will postpone and do a fresh VM instead. Thanks for the heads up – we had the same space issue with 1.2 that dogged us until we did a fresh install for 2.0.
A tip for anyone doing a fresh install.. the maps will always export in feet regardless of if you have meters set so don’t get caught out or all your maps may end up three times as big!
Ric
Thanks Ric.
Thanks for the tip on map scale as well
Rasika
Great advice Rasika, appreciated!
I have few customers with CPI 2.2 and im pretty sure they will be migrating to CPI 3.0 soon.
Regards.
No prob Alonso. Glad this helps you
Rasika
Hey Rasika,
thanks a lot, not just for this gem, but for sharing all you knowlege. In my opinion your blog is one of the best sources regarding technical difficulties and their solutions.
Keep up this outstanding work!
best regards
Matt
Thanks Matt, appreciate your kind words.
I will keep sharing my knowledge with wider community.
Rasika
does this apply to hardware appliances as well ?
If you migrate from old version to new version, this could happen in any form (VM or Physical). So my advice is to do a fresh installation & modify those default data retention settings.
HTH
Rasika
Thanks for your quick response Rasika, can we take a backup in 2.2 and restore in 3.0 after modifying those settings as we only have 1 hardware appliance and not sure how I could use the option of a fresh 3.0 install.
If you take application backup & restore, then you do not get a chance to modify those settings.
What I would do is export maps (to your PC) & then do a fresh install of PI 3.0 (this will loose all your historical data). Then import maps and manually add devices.
HTH
Rasika
has anyone encountered this issue in a gen2 appliance.. or just a vm environment..
i am new to the game.. but this is a good post.. not happy to know that you were already running below half of the max data retention period supported by PI 2.2/3.0 as documented in the admin guide and having these issues (assuming you have built your VM/appliance specs as per the gen2 appliance settings) + maybe coincidence , but did you notice any increase authentications (roams) on your wireless network with the same client auth. count you had when running 2.2?
I think main issue is in new database structure, there is no way to reclaim any space after initially allocated.
Let’s say you identify your alarms/alerst consume 100G of your DB and you deleted them. Still DB allocate 100G for alarms/alerts and not release this space. In my case 150G consumed by this (since I left default settings and not clearing them after certain days), even after TAC delete this later, disk space utilisation was same & this space is not released back.
In my case I do not want to have this issue again, so reduced those data retention policies (though I would like to have 1 year worth of history).
HTH
Rasika
Thanks Rasika.. that is the value prop of Airwave… Prime the data retention depends on 3 factors the max data retention sessions… the client session history (variable due to client auth count and roams) and the # of rows to keep.. 8 million ( fixed regardless of how much optvol you have assigned).. so even if you set the max client session history to 365 days.. if you cross 8 million rows.. you start to loose data.. its just a little weird that Cisco does it this way.. i am talking to the engineers this very topic..
Doing a fresh install would have us down for too long, since we use PI for wired and wireless, and have a lot of templates, profiles, etc. stored within.
I wonder if we change the retention settings in PI2.2 down to something akin to your modified setting (or even less), THEN do the backup and restore into 3.0, if it would help prevent this issue?
I’m curious – what was your smosvg-optvol utilization in PI2.2? We just added more disk to ours and are now at a comfortable 48%.
I’m also quite glad to see that the alarm threshold is something that can be set now. I think the disk utilization threshold was something like 60-70% before, and all logged-in users would see the alert, generating a constant flood of “Did you see this” e-mail.
Not sure.
If you do not have a choice of fresh installation, then I would check deleting some alarms/alert files and see that helps to reduce database size. If that works you should be fine with reduce those threshold and delete unwanted files from 2.2 and then backup -> restore.
HTH
Rasika
Quinfosec – do you have the resources to do a side-by-side? I modified the firewall rules to allow one additional IP with the same ruleset as original CPI and then import all the maps/configs/devices/templates over whilst they are both running. I then do a switchover to the new one once I’m sure it’s ready for prod.
We do have that option, since normally, we run PI in HA. So removing HA and then spinning up 3.0 on the former ‘secondary’ box would be fine.
I’ll have to look into the import functions, but that’s an excellent idea, thanks.
Thanks for the post. I have got the same issue. I made an upgrade from 2.2 to 3.0. The backup was working fine and then i dont work any more. Now i made some researche and found that.
DB size is 110 GB
/dev/mapper/smosvg-optvol 200G 168G 22G 89% /opt
Moved from ftp backup to NFS but dont help because:
ERROR : Cannot proceed with backup as the free space available in oracle fast recovery area (24485 MB) is less than the current database size(67584 MB).
% Internal error: couldn’t create backup file
Its only my little installation in our Company for testing with 2 WLCs and 9 Accesspoints and about 5 Switches. So now i will make a new installation. 😦
Thanks for sharing your experience with this.
Yes, do a fresh install & keep watch the disk space with modified settings.
HTH
Rasika
I made the fresh install and the changes you suggested. Now i have got the same Problem again. PI say that the diskspace is running full.
Disk Source Available Space(KB) Used Space(KB) % Used
/dev/mapper/smosvg-optvol 60821544 137830248 69 %
I Made already a disk cleanup.
Hello Navari,
I have one question, do you know how can I use CPI 3.0 as tftp server for migration of Autonomous AP to Lightweight ?
I could make this, only by using external tftp server.
Thank you, for your help.
Romaric, You can convert Autonomous APs under “Autonomous AP Migration” in CPI without requiring a manual tftp archive download.
Thanks Ric for responding to these queries. Really appreciated
Rasika
I did a ncs cleanup, its been more than 4 hours now , its stuck at stopping server, i have too many maps and 1800 devices. will it effect the prime server.
PI was upgraded from 2.2 to 3.0 3 months ago. its HA setup.
“ncs cleanup” is nearly useless (unfortunately)
Here’s another option for freeing up disk space:
1) Log into PI CLI
2) Descend into Linux shell by issuing “root” command (“shell” for PI 3.1)
3) cd /opt/CSCOlumos/tmp/temp/reports
4) Issue command “du -sh” to see how much disk space this directory and sub-
directories consume
5) You may safely delete __only__ folders beginning with “temp” (e.g. tempABCDEFG, temp0123456)
Thanks for sharing a workaround for this 🙂
we were hitting the bug “CSCux82395”
/dev/mapper/smosvg-optvol
was 98% /opt
found out under directory /opt/CSCOlumos too many files of .mat
“matlab_debug_log_ap2ap_compute_heatmap_736376_176438.mat”
Solved this issue by deleting this files using the command below . it delete all the files with the same string. and have also disabled dynamic heatmaps.
ade# rm matlab_debug_log_ap2ap_compute_heatmap_736*.mat
now the file size is :
/dev/mapper/smosvg-optvol
694G 251G 408G 39% /opt
Great post! Thanks!
Unfortunately I didn’t see it when it matters the most and now I have the /opt at 77%
/dev/mapper/smosvg-optvol 200G 146G 45G 77% /opt
Is it possible to downsize the /opt without making a fresh installation of the PI?
I already configured the retention times, disabled dynamic heatmaps, issued that ncs cleanup and I don’t have any matlab_debug*.mat files but the /opt is still only have 43Gb for a 110 Gb database.
I do not think so 😦
Rasika
Hi all,
I have error to my CPI 3.1
In my console ESXI:
/dev/mapper/smosvg-optvol 2376/256000 files 244058/1024000 blocks (check after next mount) [failed]
An error occured during the file system check
Need your help
I would suggest to work with TAC directly on these sort of issues
Rasika
Our upgrade was an inline upgrade (per the strong recommendation of our SE and TAC) from 2.2 to 3.0 and then 3.1. I recently ran into the same optvol full issue.
In our case, a combination of old MSE backups and most notably, backup files that were created during the inline upgrade, were the cause.
To find the big files (along the lines of what Olivier posted above), first drop to the shell (3.1)cd /local. Then, ‘sudo su’. After that, I used ‘du -h | sort -rh | head -20’ command to help me track down where the biggest files were.
Good to know Rich, Did removal of files help you in that instance ?
Rasika
It absolutely did. Our optvol is 1.2TB, and we went from 99% used down to 55%. Mainly, it was the backup files from the upgrade that was the space hog. I wish I could remember the exact path, but it was pretty easy to find them using those commands, and the filename was formatted so that it was pretty clear what the file was.
Hi, one thing I was just facing last week at a customer was related to a patch for PI 3.1: Patch 2 (3.1.2) seems to cause a lot of trouble but it was just this week that Cisco deferred the patch and all documentation about it completely. One of the main issues is, that after installing the patch, TACACS authentication on the PI does not work. The only solution is to wait for the TAC and BU to provide the next patch, 3.1.3 and install this over the 3.1.2… Hope this saves someone from having the same issues..
Thanks for sharing this info Patrick. I can’t believe this sort of issues with recent patches released for PI.
Something is seriously wrong with QC on these patch releases.
HTH
Rasika
Hi,
Dumped the 3.0 and installed a fresh 3.1. 72 hours later and /opt always less than 15% so it seems the problem is finally solved. 🙂
Cheers,
Vasco
Dear Rasika, greetings fro Russia and thank you for sharing this experience!
Thanks Eldar..
Hi Rasika,
with the fresh CPI 3.0 install you claimed 941Gbyte to the volume.
Can I change the OVA values (cpu, memory, disk) by myself ?
e.g. 8vCPU, 16GB RAM, 900GB Disk.
Because I often had problems with the given VA appliance disk sizes (see link below). Unfortunately also with a very small installation. (PI 2.2)
http://www.cisco.com/c/en/us/td/docs/net_mgmt/prime/infrastructure/3-0/quickstart/guide/cpi_qsg.html#pgfId-121836
Best regards
Alois
Pingback: About Cisco Prime Infrastructure 3.0 disk space – The dot 11 blog
Hi Rasika,
Are you using the same Prime Infrastructure Appliance hardware for the upgrade to CPI 3.0? i.e. PRIME-NCS-APL-K9.
As from CPI 3.0, a new hardware appliance was introduced as Gen2 appliance.
Thanks
We are using VM, not hardware appliances
Rasika